

先做个广告:如需代注册帐号或代充值Chatgpt Plus会员,请添加站长客服微信:pingzi7749
《JNIS(中文版)》是神经介入专科影响力最高的国际期刊Journal of NeuroInterventional Surgery 《JNIS》(IF 4.8)的官方中文期刊,由中国医师协会神经介入专业委员会(CFITN)联合新媒体平台「卒中视界」与《JNIS》出版方BMJ中国版权合作,于2019年4月正式发布。旨在以中文语言为我国神经介入领域医务工作者提供JNIS原版学术进展,并将更多国内优秀神经介入成果介绍给国际学界。打开一扇窗,架起一座桥。中文版编委会由176名国内顶级医学专家组成,每期《JNIS(中文版)》内容由编委精选和精译,并结合专家个人经验撰写专家评论以飨同道。
本期译者:涂义
本期点评人:段传志教授
脑卒中致残、致死率极高,如何准确预测卒中治疗中神经功能的恢复程度,对于判断预后至关重要。目前,人工智能的发展非常迅猛,已经越来越多地被应用于医学领域,一些学者尝试将人工智能用于预测卒中机械取栓术后功能及预后,其结果的准确性和预测模型的可行性到底如何?本文将为大家带来详细解读。

摘要
背景
准确预测卒中治疗中神经功能的预后至关重要,同时也具有挑战性。
目的
评估ChatGPT语言模型在预测急性缺血性脑卒中(AIS)患者机械取栓术(MT)后3个月的功能预后方面的性能,以评估ChatGPT是否可用于准确预测机械取栓术后3个月的改良Rankin量表(mRS)评分。
方法
对163名接受MT治疗的AIS患者的临床、神经影像学和手术相关数据进行了回顾性分析。使用Cohen's κ评估ChatGPT的精确预测和二分法预测与实际mRS评分之间的一致性。使用现有的有效评分(MT-DRAGON)与二分法预测结果的一致性分析以衡量ChatGPT的增益价值。
结果
ChatGPT在术后3个月时的精确预测和二分法的mRS评分的一致性分别为一般(κ=0.354,95%CI 0.260至0.448)和良好(κ=0.727,95%CI 0.620至0.833),在总体和亚组预测中均优于MT-DRAGON评分。对于发病到入院时间较短、远端闭塞和改良脑梗死溶栓分级(mTICI)较好的患者,ChatGPT预测的一致性更高。
结论
ChatGPT可充分预测机械取栓术后AIS患者的短期功能预后,并且优于现有的风险评分。将人工智能模型融入到临床实践中有望用于患者的治疗管理,进一步改良和完善这些模型对提高卒中治疗的准确性至关重要。
引言
及时干预和准确预测功能预后对优化卒中治疗策略和改善患者预后起着至关重要的作用。机械取栓术可快速、精确地清除脑血管中的血栓,为急性缺血性卒中的治疗带来了革命性的变化。然而,预测术后功能预后目前仍是一项挑战。准确预测功能预后(通常使用mRS评分进行评估)在卒中的治疗中至关重要,因为其不仅能让医护人员就治疗方案、康复计划和资源分配做出明智的决定,同时还能帮助医务人员满足患者及其家属的期望。
现有的预测模型,如ASTRAL评分和iScore评分等,是在机械取栓(如支架取栓和抽吸取栓)广泛应用前开发的。上述模型由于缺乏神经影像学和手术相关数据等重要的预后信息,可能会影响其整体性能。MT-DRAGON评分改编自MRI-DRAGON评分,通过整合MT手术和成像模式的预后数据来解决上述局限性。MT-DRAGON评分包括年龄、性别、血糖水平、闭塞部位、美国国立卫生研究院卒中量表(NIHSS)基线评分、静脉注射组织纤溶酶原激活剂、ASPECT评分和动脉穿刺时间等信息。在验证研究中,所有MT-DRAGON评分≥11分的患者在急性缺血性卒中90天后均表现出不良预后(mRS评分>2)。然而,这些模型不仅临床变量范围有限,而且还假设与预后的对数值之间存在线性关系。这种过度简化可能会影响其在真实场景中准确预测结果的能力。
ChatGPT是由OpenAI开发的一种高级语言模型,使用深度学习框架根据输入内容模拟人类的响应。在多个庞大的数据集上进行训练后,ChatGPT展示了理解和生成连贯文本的卓越能力,已成为医学各领域的重要工具。
本研究主要目的是评估ChatGPT预测值与MT术后3个月的实际mRS评分之间的一致性。为了评估这种预测能力的意义,作者将ChatGPT的表现与MT-DRAGON评分进行了对比。
方法
研究设计和结果
本研究为一项观察性回顾研究,纳入2020年3月至2021年6月期间连续163例接受MT治疗的AIS患者的临床、神经影像学和手术相关数据。选择了年龄≥18岁、卒中前mRS评分≤3分、确诊为前循环AIS并接受MT治疗的患者。死亡患者(mRS评分为6分)不包括在内,因为较难将他们的死亡归因于与AIS或MT治疗相关因素。在预期κ为0.7和最大CI宽度为0.2的条件下,进行Cohen's κ检验从而得出两个mRS评分预测值之间经机会调整后的一致性所需的样本量为135,计算方法如前所述。本研究获得了当地伦理委员会的批准(批准号CE 72-23),研究中使用的程序符合1964年《赫尔辛基宣言》及其后来修订版中的伦理标准。鉴于本研究的低风险性和回顾性,无需获得知情同意,也未与受试者联系。
ChatGPT交互
向ChatGPT提供了163个病例(V.3.5,2023年5月24日)的综合信息,涵盖每位患者的临床、神经影像和手术相关数据(去除了个人信息),其中包括:年龄、性别、既往的mRS评分、合并症(心房颤动、心力衰竭、高血压、糖尿病、血脂异常、冠心病、吸烟、癌症)、当前用药(口服抗凝药、抗血小板药、他汀类药物)、发病到入院时间(分钟)、入院NIHSS评分、入院收缩压(mmHg)、入院时的血糖(mmol/L)、ASPECT评分、静脉溶栓给药、发病到静脉溶栓间隔时间(分钟)、闭塞部位、是否存在串联闭塞、发病到穿刺间隔时间(分钟)、MT期间的全身麻醉、mTICI的最终评分、取栓总次数以及再通时间(分钟)。未涉及敏感健康信息。
在研究开始时,对ChatGPT进行了迭代训练提示,其中包含了预测mRS评分的各种要求。特别要求对mRS评分进行“唯一”预测,以防止出现二分法结果(如mRS评分1或2),并迫使模型生成单一的预测数值。最后的提示是"对具有以下特征的前循环缺血性卒中患者机械取栓术后3个月的mRS值进行唯一预测"。尽管如此,在少数特殊情况下,模型还是产生了二分法应答例如mRS 0-1分或同等值。在这种情况下,则记录最高的mRS分数。
为了避免交互式学习,所有提示都出现在不同的对话中,并且没有对模型的分数预测进行任何调整。图1显示了最终提示的示例以及相应的ChatGPT预测值。

图1 与ChatGPT对话的示例及术后3个月mRS预测值
统计分析
连续变量采用中位数和IQR,分类数据采用绝对频率和相对频率。计算每位患者的MT-DRAGON评分,≥11分表示预后不良(mRS评分>2),<11分表示预后良好(mRS评分≤2)。根据患者的确切值和ChatGPT预测的3个月mRS评分,采用相同的临界值将患者分为两组:预后良好组(mRS评分0-2分)和功能预后不良组(mRS评分3-5分)。实际术后3个月mRS评分与ChatGPT预测值之间的一致程度,以及ChatGPT和MT-DRAGON的二分法预测值之间的一致程度,均使用κ统计量进行评估。该统计量的范围从完全一致(κ=1)到纯属偶然的一致(κ=0),标准一致类别为差(k=0至0.20)、一般(κ=0.21至0.40)、中等(κ=0.41至0.60)、好(κ=0.61至0.80)和非常好(κ=0.81至1.00)。绘制Bland-Altman图以描述术后3个月mRS预测评分与真实评分之间的差异分布。Bland-Altman图是一种可视化工具,不仅可用于评估配对测量中观察到的平均差异,还可用于评估数据点的分散性以及差异大小与测量尺度之间的关系。平均差异线上下的水平线对应于95%的一致性界限,设定为偏差±1.96倍SD。对mRS评分的真实组和预测组之间的一致性进行了评估。使用SPSS 26.0软件进行统计分析,显著性水平设定为P<0.05。<>
结果
163名患者发生卒中年龄的中位数为74.0岁,64名患者(39.3%)为男性。卒中前,121名患者(74.2%)合并轻度或无残疾(mRS评分0-1),42名患者(25.8%)有中度残疾(mRS评分2-3)。常见合并症包括心房颤动(48.5%)、动脉高血压(70.6%)和血脂异常(61.3%)。NIHSS评分中位数为14.0(IQR 9.0),ASPECTS评分中位数为9.0(IQR 2.0)。最常见的闭塞部位为大脑中动脉(60.1%),82.8%的患者实现了近乎完全的再灌注(mTICI评分2b-3)。受试者特征见表1。
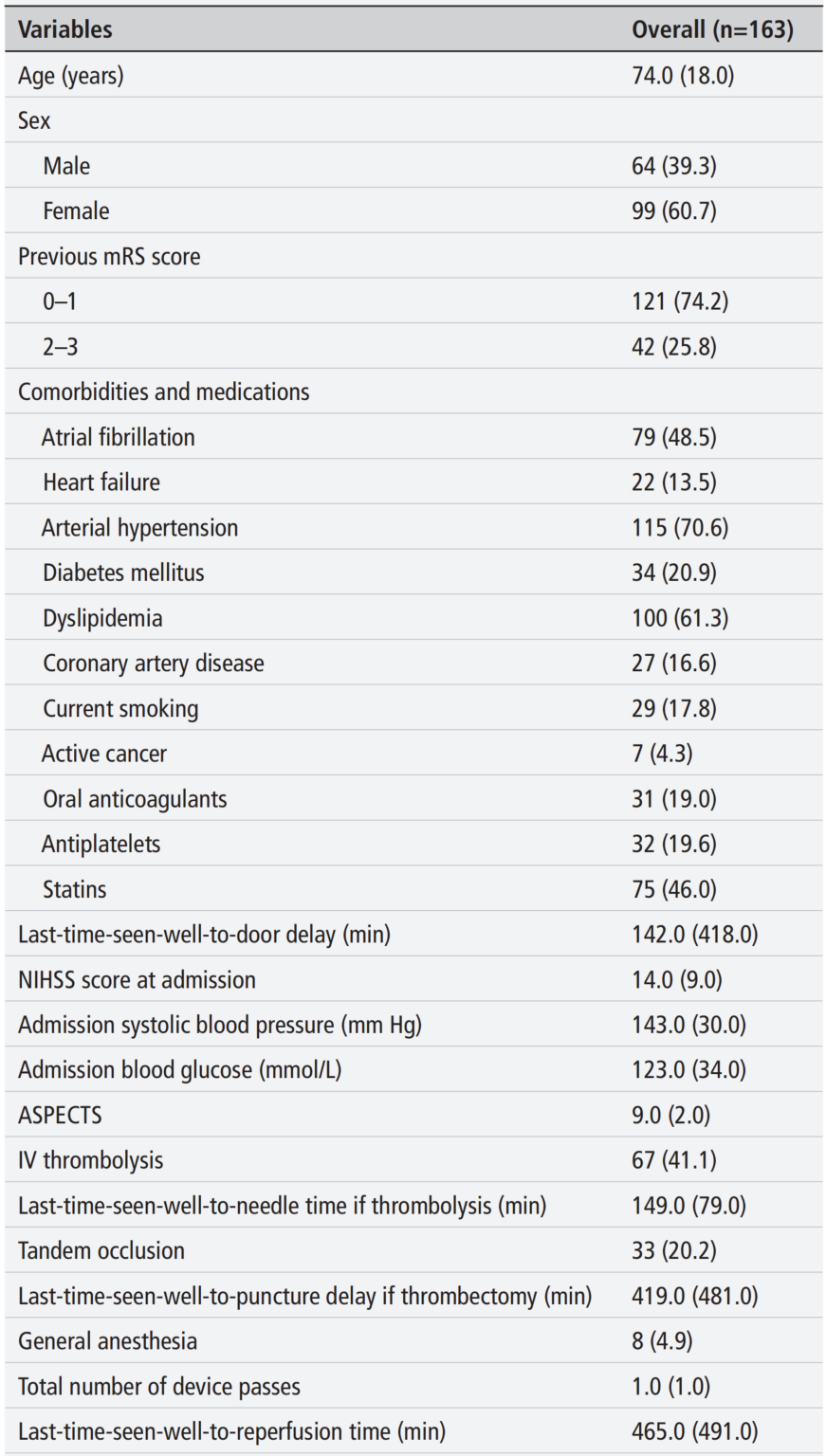
表1 受试者特征 分类变量的数值表示为n(%),连续变量的数值为中位数(IQR)。
ChatGPT可准确预测49.1%的AIS后3个月的mRS评分,总体一致性尚可(κ=0.354,95%CI 0.260至0.448)。ChatGPT在总体和亚组预测中的表现均优于MT-DRAGON(表2)。
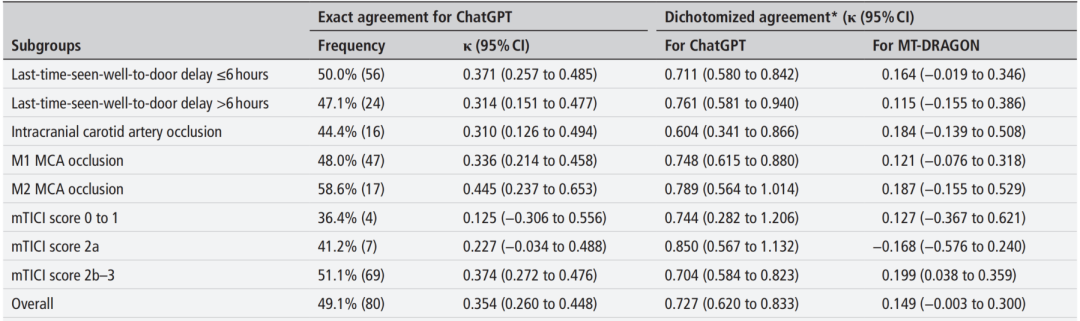
表2 一致性分析 *定义为实际二分化mRS结果(0-2为良好结果,3-5为不良结果)与ChatGPT和MT-DRAGON预测的二分化mRS评分之间的一致性。
ChatGPT与二分法结果的一致性较好(κ=0.727,95%CI 0.620至0.833),但MT-DRAGON评分的一致性较差(κ=0.149,95%CI -0.003至0.300)。对于发病到入院时间较短、颅内颈动脉和M1段闭塞以及mTICI评分较好的患者,ChatGPT预测结果和真实mRS评分一致性较高。Bland-Altman图显示偏差接近零(-0.01),95%的一致性界限为(-2.08;2.08),表明两种测量方法之间存在轻微的系统性差异(图2)。
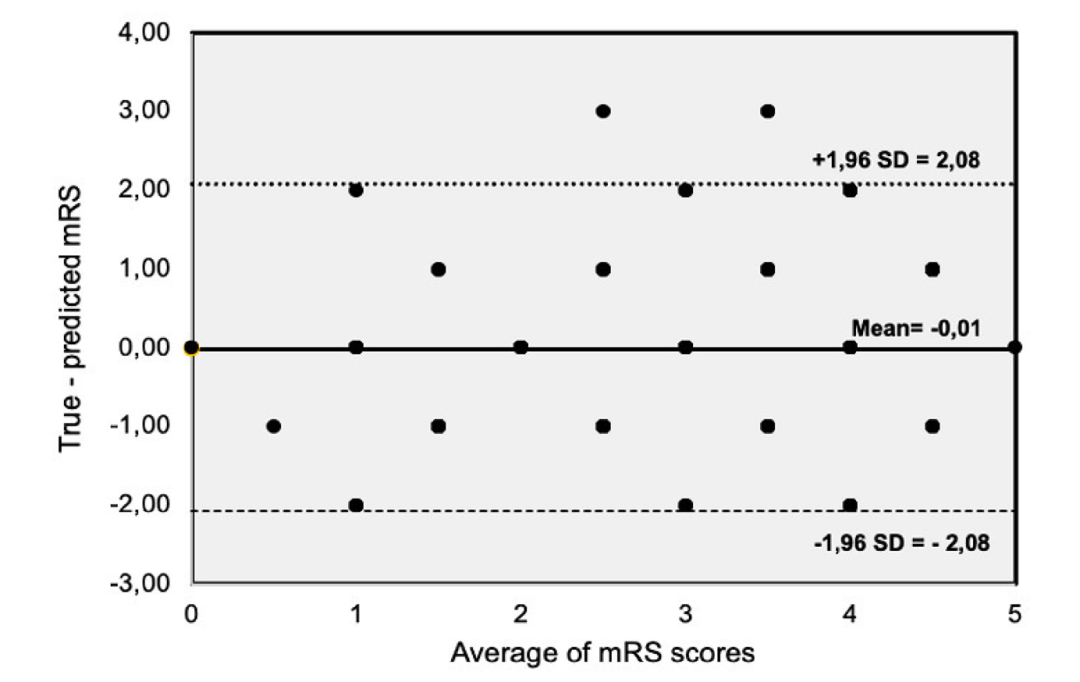
图2 术后3个月时mRS准确评分与ChatGPT预测评分之间差异的Bland-Altman分析
讨论
尽管治疗策略在不断进步,但大血管闭塞性卒中患者的功能恢复仍难以预测且具有挑战性。近来深度学习模型已证明了其预测大血管闭塞性卒中患者预后的能力,尤其是在结合影像数据时,其表现超越神经科医生。然而,即使能够不受限制地获取原始数据和代码,复制推广其他研究团队训练的机器学习模型也是一项复杂的挑战。
本研究首次尝试评估大型语言模型(如ChatGPT)在预测接受MT治疗的AIS患者短期功能预后方面的潜力。研究发现,ChatGPT在对AIS术后3个月时的真实mRS评分分别进行精确预测和二分预测上达到了相当良好的一致性,这表明ChatGPT有潜力成为提供患者功能早期预后信息的工具。有了上述信息,医生就能更快地优化随访评估的时间和频率,从而提供更加个性化和及时的护理,从而在临床实践中优化资源分配,加强对患者的护理。
通过准确预测功能预后,医生可以预测不同预后患者的需求。例如,预测结果良好的患者可能需要较少的复诊次数,从而减轻医疗资源的负担,而预测结果较差的患者则可能受益于更个性化的护理。此外,对功能预后的早期预测可促进积极的护理规划和患者咨询。同时,患者及其家属通过了解康复的预期能更好地为未来可能遇到的挑战做好准备,从而提高医患的满意度和整体护理质量。
亚组分析显示,对于部分至完全再灌注(mTICI评分2b-3)、远端闭塞以及从发病到就诊时间较短的患者,ChatGPT的准确预测更为准确。上述因素是AIS后良好结果的公认预测因素,这表明ChatGPT的优秀性能可能得益于这些病例具有较低的死亡率和更可预测的临床轨迹,从而能够获取到更多的数据。
然而本研究也存在一定局限性。尽管MT-DRAGON是接受MT治疗的前循环AIS患者唯一经过验证的评分,但其对mRS评分二分化的预测与实际功能预后的一致性有限。造成这种差异的原因可能是MT-DRAGON仅在卒中发生后8小时内接受治疗的患者中得到验证,而本研究的患者中有41.7%在8小时后才接受MT治疗。此外,本研究的ChatGPT模型不仅包括MT-DRAGON变量,还包括可提高ChatGPT预测准确性的其他因素。此外,MT-DRAGON中基于弥散加权成像的ASPECTS部分可能无法与本研究的ASPECT评分直接比较,后者是通过入院时的头部CT确定的。未来有必要开展进一步研究,将ChatGPT的性能与纳入MT相关变量的新兴风险评分以及受试者特征相符的风险评分进行比较。
此外,ChatGPT的预测准确性还受其训练数据库的影响。用于训练ChatGPT的数据集若包含了更多具有近端血栓、中度残疾和成功再灌注的病例,则能更好地了解与这些病例功能预后相关的因素。数据库的扩大提高了ChatGPT为此类病例提供准确预测的能力。与轻度或重度残疾或再灌注不成功的患者相比,中度残疾和成功再灌注的患者可能具有更直接的临床特征,这使得ChatGPT更容易预测这些患者的预后。
另一个限制因素是人工智能聊天机器人可能会产生不准确的信息(即“幻觉”,hallucinations)或过早切断输出(截断错误,truncation errors)。为了减轻这些影响,本研究使用了少于4096个词组的标准化提示,并从分析中排除了缺少数据的变量。作者认为这种方法比归因缺失值更合适,因为归因值可能无法准确反映缺失变量的真实值,并可能带来额外的误差来源。
ChatGPT是目前使用最广泛的大型语言模型,但必须承认,在研究开发过程中,其知识库仅限于2021年之前的信息,这可能会妨碍获取最新的临床试验数据。此外,本研究的样本主要包括梗死核心相对较小的患者(如ASPECT评分中位数为9分)。这种数据可用性的局限性限制了本研究结果对大梗死核心卒中病例的推广性,尤其是考虑到所有关于大梗死核心卒中取栓术的重要研究都是在2021年之后发表的,未来的更新可能会提高准确性,但会影响研究的可重复性。此外,还需要将ChatGPT的性能与Bard或Bing等其他大型语言模型进行比较。
尽管面临重重障碍,ChatGPT对于卒中的诊断和治疗仍显示出广阔的应用前景。其功能涵盖广泛,包括分析患者症状、进行全面的鉴别诊断、评估风险、提供转诊建议及患者宣教。例如,如果患者出现身体一侧突然无力等症状,ChatGPT可以处理该信息,同时根据各种因素评估患者的整体卒中风险。这种早期评估有助于在诊断的早期阶段识别潜在的卒中相关问题。此外,尽管当前版本的ChatGPT不支持图像上传,但这一功能有望在未来的ChatGPT 4.0等迭代版本中实现。该功能的加入将大大提高应用程序的实用性,用户可以上传神经影像结果,从而方便对其进行解读和分析。ChatGPT还有可能协助进行风险分层、优化治疗方法、在康复期间为患者提供支持。它可以根据每位患者的病史、现有健康状况和用药偏好量身定制建议。通过为每位患者量身定制治疗计划,ChatGPT可以帮助医务人员确定最合适的干预措施,从而降低不良事件发生率并改善整体疗效。
结论
本研究评估了基于人工智能的生成语言模型ChatGPT预测MT治疗术后的前循环AIS患者短期功能预后的准确性。ChatGPT与AIS术后3个月的真实mRS评分显示出令人满意的一致性,显示了其在提供患者功能恢复早期预后信息方面的潜力。在临床实践中应用ChatGPT有助于优化资源分配和加强患者护理。然而,为确保临床决策的准确性和可靠性,还需要进一步改进算法并加强彼此之间的协作。目前ChatGPT的发展可谓非常迅猛,已经被越来越多地应用到各个领域中。在医学领域,ChatGPT也有着较为自己独特的优势。
本研究将163名接受机械取栓治疗的急性缺血性卒中患者的临床资料、神经影像学和手术相关数据进行了回顾性分析,选取ChatGPT语言模型,使用Cohen's κ评估ChatGPT的精确预测和二分法预测与实际mRS评分之间的一致性,评估ChatGPT在预测急性缺血性脑卒中患者机械取栓术后3个月mRS评分的准确性。结果显示:ChatGPT与术后3个月的真实mRS评分有着良好的一致性。对于从发病到入院时间较短、远端闭塞和mTICI评分较好的患者,ChatGPT的一致性更高。因此认为ChatGPT语言模型可充分预测机械取栓术后AIS患者的短期功能预后,这表明ChatGPT有潜力成为提供患者功能恢复的早期预后信息的工具。这一结果为临床卒中的防治策略提供了一个良好的预测模型。
随着ChatGPT技术的快速发展,ChatGPT作为诊断和治疗卒中的工具显示出广阔的应用前景。采用ChatGPT技术早期评估有助于在诊断过程的早期阶段识别潜在的卒中相关问题。除此之外,ChatGPT还有可能协助进行风险分层、优化治疗方法,以及在康复治疗方面为患者提供支持。研究者可以根据每位患者的病史、现有健康状况和用药偏好量身定制。尤其是对于卒中患者,通过为每位患者量身定制治疗计划,ChatGPT可以帮助医护人员确定最合适的干预措施,从而降低不良事件发生率并改善整体疗效。
虽然ChatGPT预测模块的建立和实施尚处于发展阶段,但是相信在今后,人工智能模型融入临床实践必将成为今后多学科融合指导临床救治的一个热点,ChatGPT技术在卒中防治方面将为我们提供更加合理、优选的治疗计划。

本文链接:https://www.qh-news.com/chatgpt/41.html
chatgpt官网中文版appchatgpt官网在哪里chatgpt官网入口是什么版本chatgpt官网中文设置微软chatgpt和官网的区别chatgpt官网价格手机登录chatgpt官网后怎么用chatgpt要从官网打开吗chatgpt官网现在可以注册了吗怎么打开chatgpt官方网址







